Comandar y Conquistar: Plan de Estrategia de Pruebas para Empresas
Pistas paralelas y transparencia que comienzan en las primeras etapas del desarrollo.
1. Introducción
En el complejo panorama del software actual, entregar aplicaciones de alta calidad, resilientes y con buen rendimiento no es un lujo, es un requisito. Esta estrategia se aleja del modelo tradicional donde las pruebas son una fase final y separada. En su lugar, integra el aseguramiento de la calidad en cada etapa del ciclo de vida del desarrollo de software.
Este documento describe un enfoque proactivo diseñado para “Comandar y Conquistar” la complejidad del testing de software. Esto se logra mediante la incorporación de una estrategia de pruebas multicapa paralela a lo largo de todo el proceso: desde la planificación y diseño inicial, pasando por el desarrollo e integración, hasta el despliegue final y monitoreo. Al considerar la calidad desde el principio, construimos confianza de manera incremental y aseguramos que nuestros sistemas sean robustos desde el componente individual hasta la experiencia del usuario final.
El núcleo de nuestra metodología es el desarrollo de pruebas en paralelo, donde las pruebas unitarias, pruebas de integración y pruebas de extremo a extremo se inician desde el momento en el que los criterios de aceptación del negocio (Acceptance Criteria) están definidos. Este enfoque promueve la transparencia, la colaboración y la detección temprana tanto de fallas del sistema como de problemas de diseño de pruebas. Es particularmente valioso cuando los miembros del equipo no están familiarizados con todas las aplicaciones involucradas, ya que garantiza que el intercambio de conocimientos ocurra continuamente durante todo el proceso de desarrollo.
2. Estrategia de Pruebas Multicapa Paralela
Nuestra estrategia de pruebas consta de tres capas complementarias que pueden trabajar en paralelo desde el comienzo del desarrollo. Cada capa sirve un propósito específico y es igualmente crítica para garantizar la calidad del software:
- Pruebas Unitarias: Verifican que las unidades individuales de código funcionen correctamente de forma aislada.
- Pueden comenzar en el momento en que se definen los criterios de aceptación del negocio.
- Pruebas de Integración: Aseguran que los diferentes módulos y servicios interactúen correctamente.
- Pueden comenzar tan pronto como se definan la infraestructura en la nube y los contratos de servicio.
- Pruebas de Extremo a Extremo: Validan los recorridos completos del usuario y los flujos de negocio en todo el sistema.
- Pueden comenzar en el momento en que se definen los criterios de aceptación - para la fase de planificación, incluso antes de que comience el desarrollo. Para su ejecución, requieren un entorno estable pero aun así, pueden desarrollarse en paralelo.
3. Capa 1: Pruebas Unitarias
Objetivo: Verificar que las unidades individuales y aisladas de código (por ejemplo, funciones, métodos o componentes) funcionen correctamente. Esta es nuestra primera línea de defensa contra los errores.
Alcance:
- La parte más pequeña comprobable de una aplicación.
- Todas las dependencias (como bases de datos o APIs externas) son simuladas o sustituidas.
- Enfoque en la lógica de negocio, casos extremos y corrección algorítmica dentro de una sola unidad.
Características Clave:
- Rápidas: Una suite completa debe ejecutarse en segundos o unos pocos minutos.
- Aisladas: Una prueba fallida apunta directamente a la unidad específica de código que está rota.
- Propiedad del Desarrollador: Escritas por los mismos desarrolladores que escriben el código de la funcionalidad, a menudo siguiendo el Desarrollo Dirigido por Pruebas (TDD).
Herramientas Recomendadas:
- JavaScript/TypeScript: Jest, Vitest
- Java: JUnit, Mockito
- .NET: NUnit, xUnit
- Go: Go testing package, Testify
- Python: unittest, pytest
Propiedad: Equipos de Desarrollo.
Criterios de Éxito:
- Un alto nivel de cobertura de código significativa (objetivo: >80%).
- Las métricas de calidad del código (por ejemplo, complejidad ciclomática, duplicación) cumplen con los umbrales definidos.
- Todas las pruebas unitarias deben pasar en el pipeline CI/CD antes de permitir una fusión de código.
Deliverables:
- Una suite completa de pruebas unitarias que cubran todo el código nuevo y modificado. Estas se encuentran junto al código de producción, asegurando que se mantengan y actualicen a medida que el código evoluciona.
4. Capa 2: Pruebas de Integración
Objetivo: Asegurar que los diferentes módulos, servicios o componentes interactúen correctamente. Estas pruebas verifican la “fontanería” de la aplicación.
Alcance:
- Interacciones entre servicios (por ejemplo, comunicación API-a-API).
- Comunicación con sistemas externos como bases de datos, cachés y colas de mensajes.
- Verificación de funcionamiento de APIs, sistems de autenticación y health checks.
Características Clave:
- Más lentas que las pruebas unitarias ya que involucran comunicación de red y servicios en ejecución.
Herramientas Recomendadas:
- Pruebas de API: Postman (con Newman para automatización), Supertest
- Gestión de Entornos: Testcontainers, Docker Compose
Propiedad: Equipo de CloudOps / DevOps, con soporte de los equipos de desarrollo.
Criterios de Éxito:
- Flujo de datos exitoso y comunicación entre servicios integrados.
Deliverables:
- La confirmación de que los servicios y componentes clave funcionan juntos como se espera.
5. Capa 3: Pruebas de Rendimiento
Objetivo: Validar los requisitos no funcionales, asegurando que la aplicación sea rápida, escalable y estable bajo las condiciones de carga esperadas. Alcance:
- Recorridos críticos del usuario y endpoints de API críticos para el negocio.
- Capacidad de infraestructura y puntos de ruptura.
- Comportamiento del sistema durante períodos prolongados (pruebas de resistencia).
Metodología: Todas las pruebas de rendimiento deben estar precedidas por un Plan de Pruebas de Rendimiento formal, que estandariza el proceso. Este plan responde cuatro preguntas clave:
- QUIEN: ¿Quién es el responsable de definir, ejecutar y analizar la prueba? Esto asegura que haya claridad en la propiedad y responsabilidad. A mayores, se puede definir un recurso “backup” en caso de que el responsable principal no esté disponible, así como responsables de quién valida y aprueba los resultados.
- POR QUÉ: ¿Cuál es el impulsor principal de esta prueba? Comprender la razón (por ejemplo, el lanzamiento de una nueva funcionalidad, preparación para un evento de alto tráfico como el Black Friday, o investigación de una ralentización en producción) ayuda a resaltar las dependencias e indica si otros equipos o aplicaciones también podrían necesitar realizar pruebas de rendimiento.
- CASOS DE USO:: ¿Cuáles son las funcionalidades reales, de cara a usuarios finales, que este test de rendimiento debe cubrir? Esto ayuda a otros a entender el contexto y las implicaciones de los resultados de la prueba.
- QUÉ: ¿Qué servicios, APIs y componentes de infraestructura están en el alcance?
- CUÁNDO: Fecha planificada para la ejecución de la prueba.
- CÓMO: ¿Cuál es la metodología de prueba (carga, estrés, resistencia)? ¿Cómo se prepararán los datos y se manejará la autenticación? Y lo más importante: ¿Cómo se monitorizarán y recopilarán los resultados de la prueba? Los tiempos de respuesta de la API y los códigos de estado pueden estar todos en verde en las APIs estándar, pero cuando hay procesos asíncronos, colas o trabajos en segundo plano involucrados, los resultados reales de una prueba de rendimiento pueden estar ocultos tras bambalinas.
- CUÁNTO: ¿Cuáles son los perfiles de carga esperados (normal vs. pico)? ¿Cuáles son los Objetivos de Nivel de Servicio (SLOs) específicos y medibles que definen el éxito (por ejemplo, tiempo de respuesta p95 < 500ms, tasa de error < 0.1%)?
- RESULTADOS: Una vez completada la prueba, los resultados deben documentarse y compararse con los SLOs definidos. Cualquier desviación debe investigarse y abordarse, así como determinar si la prueba resultó satisfactoria, no satisfactoria o si se necesita una nueva prueba.
Consulte el Apéndice A para la Plantilla detallada del Plan de Pruebas de Rendimiento que se puede completar antes de iniciar cualquier prueba de rendimiento.
Herramientas Recomendadas:
- Generación de Carga: k6, Gatling, JMeter, Artillery
- Monitoreo: Datadog, Grafana, New Relic, herramientas de monitoreo de su proveedor de nube y servicios de insights.
Propiedad: Equipos de Ingeniería de Rendimiento / SRE / DevOps, en colaboración con los Equipos de Desarrollo.
Criterios de Éxito:
- El sistema debe cumplir con todos los SLOs definidos bajo el escenario de carga pico especificado.
- No se observan fugas de memoria o degradación del rendimiento durante las pruebas de resistencia.
Deliverables:
- La plantilla del Plan de Pruebas de Rendimiento completada.
- Los scripts de prueba de rendimiento versionados en un repositorio al que toda la organización pueda acceder.
- Un informe completo de pruebas de rendimiento que documente, en base a la plantilla, que de facto, las pruebas han sido realizadas en base a los criterios definidos, y los resultados de las pruebas comparados con los SLOs.
6. Capa 4: Pruebas de Extremo a Extremo (E2E)
Objetivo: Simular escenarios reales de usuario de principio a fin, validando todo el flujo de trabajo de la aplicación a través de la interfaz de usuario y todos los servicios backend. Esto proporciona el nivel más alto de confianza de que el sistema en su conjunto funciona para el usuario final.
Alcance:
- Flujos de negocio críticos (por ejemplo, registro e inicio de sesión de usuario, proceso de búsqueda a compra, generación de informes).
- Interacciones del usuario a través de múltiples páginas y componentes.
Características Clave:
- El tipo de prueba más completo.
- El más lento y frágil debido a su dependencia de un entorno completamente desplegado e integrado.
- Debe reservarse para los escenarios de “camino feliz” más críticos.
Herramienta Recomendada:
Para mitigar la complejidad inherente y la fragilidad de las pruebas E2E, nuestro estándar es @lab34/flows. Este framework moderno se elige por su enfoque en crear pruebas legibles, mantenibles y potentes que realmente representan los recorridos del usuario.
Beneficios de @lab34/flows:
- Sintaxis Declarativa: Las pruebas se escriben de una manera que describe claramente la intención del usuario, haciéndolas fáciles de entender tanto para las partes interesadas técnicas como no técnicas.
- Orquestación Robusta: Simplifica las interacciones complejas, como gestionar la autenticación, manejar operaciones asíncronas y encadenar múltiples llamadas API y acciones de UI.
- Mantenibilidad: Al centrarse en flujos en lugar de selectores de UI individuales, las pruebas son más resistentes a cambios menores en la UI de la aplicación.
Propiedad: Todos los miembros del equipo TIC, desde diseñadores, desarrolladores y Equipos de Ingeniería de QA / Automatización.
Criterios de Éxito:
- Todos los recorridos críticos del usuario pasan exitosamente en un entorno similar a producción antes de un lanzamiento.
- Las pruebas se ejecutan en un horario regular (por ejemplo, compilaciones nocturnas) para detectar regresiones temprano.
Deliverables:
- Una suite de pruebas E2E que cubra todos los flujos de usuario críticos, escrita utilizando el framework @lab34/flows, asegurando que sean legibles y mantenibles. Estas pruebas deben almacenarse en un repositorio accesible para toda la organización.
- Un informe de resultados de pruebas E2E que detalle las pruebas ejecutadas, los resultados y cualquier problema encontrado.
- Capturas de pantalla, si aplica, para documentar la ejecución.
Timeline de Implementación para todas las actividades paralelas
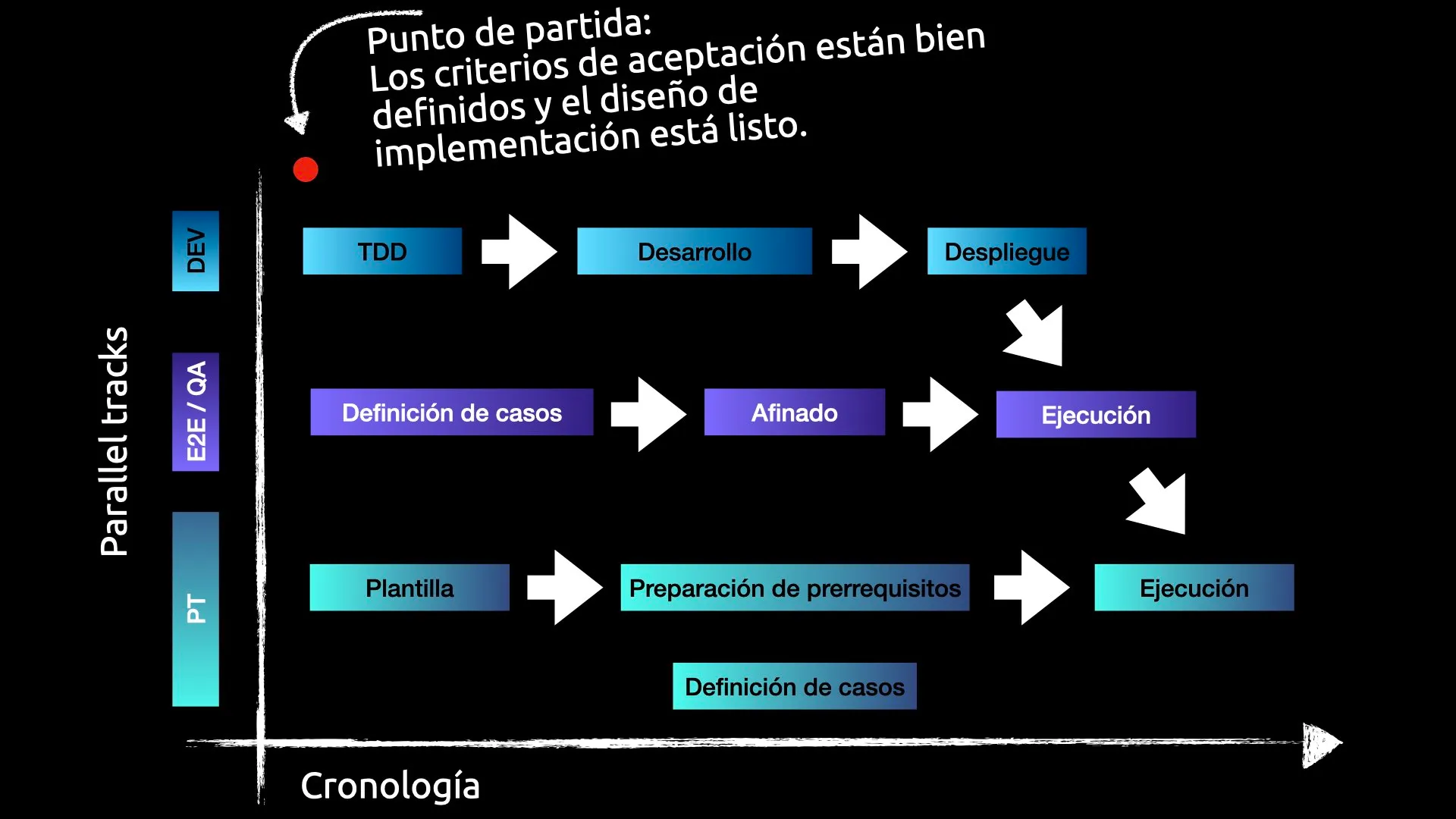
Como punto de partida, recomendamos que todas las capas comiencen en paralelo tan pronto como se definan los criterios de aceptación del negocio, así como las guías de implementación.
Una vez que estos requisitos están bien definidos, tanto TDD, la definición de los casos de testing e2e y la creación de la plantilla del plan de pruebas de rendimiento (si aplica) pueden comenzar inmediatamente.
No se espera que el equipo de E2E tenga una suite completa, ya que durante el desarrollo, los programadores pueden detectar checks adicionales que deben ser cubiertos. Es por ello que las pruebas e2e deben de ser supervisadas por el equipo de desarrollo, sin que ello suponga que el equipo de QA no pueda comenzar la definición con antetioridad.
El mismo caso sucede con las pruebas de rendimiento. La plantilla del plan de pruebas de rendimiento debe iniciatse antes de que el código esté desplegado, e igual que para las pruebas e2e, el equipo de desarrollo debe supervisar la definición de los endpoints y flujos a probar, ya que durante el desarrollo pueden detectarse endpoints adicionales que deban ser cubiertos (así como ayudar a identificar pre-requisitos).
En resumen, si tanto los casos de uso y las definiciones de las pruebas de rendimiento, así como el conocimiento de cómo ejecutarlos, se pone en común (en repositorios accesibles para todos los equipos):
- Se eliminan bottlenecks de dependencias entre equipos.
- Se tiene una visión global de los requisitos y comprobaciones que deben ser cubiertos.
- Se fomenta una cultura de colaboración, propiedad y responsabilidad compartida, ya que todos pueden supervisar, contribuir y aprender de las pruebas.
Más información sobre cómo implementar
Trabajamos estrechamente con nuestros clientes para implementar esta y otras estrategias de forma eficaz. Si desea saber más sobre cómo implementar esta estrategia en su organización, contáctenos en hola@lab34.es.
Contamos con perfiles de primer nivel, desde desarrolladores sénior hasta arquitectos y ex testers de control de calidad de Apple, que pueden ayudarle a implementar pruebas y otras estrategias en su organización.
Bonus: Plantilla del Plan de Pruebas de Rendimiento
Esta plantilla sirve como un registro oficial para definir el alcance, la metodología y los criterios de éxito para las pruebas de rendimiento. Su propósito es estandarizar y asegurar la consistencia y trazabilidad de las pruebas.
Colocar este documento en un lugar donde todas las partes interesadas puedan acceder a él (por ejemplo, una unidad compartida, herramienta de gestión de proyectos o repositorio de control de versiones) es crucial para la transparencia y colaboración, donde cualquiera, incluso los nuevos miembros del equipo, puede entender el contexto y los detalles de las pruebas de rendimiento realizadas en el pasado, y entender cómo planificar las futuras.
¿Necesitas planificar una prueba de rendimiento? Usa esta plantilla para comenzar: Descarga la Plantilla del Plan de Pruebas de Rendimiento.
Información General
- Nombre del Proyecto/Cambio:
- Fecha de Solicitud:
- Equipo Solicitante:
- Líder Técnico:
- Breve Descripción del Cambio: (por ejemplo, Implementación de un nuevo algoritmo de búsqueda en la API de propiedades para mejorar la eficiencia).
QUIÉN: Responsabilidades y Propiedad
- Responsable de la Prueba: (Nombre y rol del individuo o equipo responsable de definir, ejecutar y analizar la prueba).
- Recurso de Respaldo: (Nombre y rol del individuo o equipo que puede actuar como respaldo si el responsable principal no está disponible).
- Validador de Resultados: (Nombre y rol del individuo o equipo responsable de revisar y aprobar los resultados de la prueba).
POR QUÉ: La Justificación para las Pruebas
Esta sección explica el impulsor principal de la prueba. Comprender la razón es crucial para el contexto y para identificar impactos potenciales en otros equipos o sistemas.
- Impulsor Principal: (por ejemplo, El lanzamiento de una nueva funcionalidad, preparación para un evento de alto tráfico como el Black Friday, investigación de una ralentización en producción, o validación proactiva de un cambio arquitectónico reciente).
- Dependencias Conocidas: (Lista cualquier otro equipo o aplicación que pueda verse afectada por este cambio o de la que dependa este cambio, lo que podría justificar sus propias pruebas de rendimiento).
CASOS DE USO: Funcionalidades Críticas
Esta sección describe las funcionalidades reales, de cara a usuarios finales, que este test de rendimiento debe cubrir. Esto ayuda a otros a entender el contexto y las implicaciones de los resultados de la prueba.
- Funcionalidades Clave a Probar: (por ejemplo, Búsqueda de propiedades, proceso de reserva, generación de informes).
- Impacto en el Usuario Final: (Describe cómo estas funcionalidades afectan la experiencia del usuario final y por qué su rendimiento es crítico).
- Escenarios de Usuario: (Proporciona ejemplos específicos de cómo los usuarios interactúan con estas funcionalidades en situaciones del mundo real).
QUÉ: Componentes a Probar
Esta sección identifica todos los elementos del sistema involucrados en la prueba.
1. Funcionalidades y Endpoints Clave
Especifica las URLs, servicios o funciones específicas a probar. Agrega tantas filas como sea necesario.
| Endpoint / Función | Método HTTP | Breve Descripción |
|---|---|---|
| (Ejemplo) /api/v2/properties/search | GET | Buscar alquileres vacacionales |
2. Infraestructura Involucrada
Especifica los componentes de infraestructura que soportarán la carga.
- Servidores de Aplicación:
[por ejemplo, Clúster Kubernetes 'webapp-prod'] - Bases de Datos:
[por ejemplo, Instancia de base de datos 'db-main-prod' (MongoDB)] - Sistemas de Caché:
[por ejemplo, Clúster Redis 'cache-prod'] - Balanceadores de Carga:
[por ejemplo, Google Cloud Application Load Balancer] - Dependencias Externas Críticas:
[por ejemplo, API de Stripe para pagos, Auth0 para autenticación]
CUÁNDO: Cronograma de la Prueba
- Fecha Planificada para la Ejecución de la Prueba:
[por ejemplo, 2024-07-15]
CÓMO: Metodología de Prueba
Esta sección detalla cómo se configurará y ejecutará la prueba.
1. Tipo de Prueba de Rendimiento
Selecciona el tipo principal de prueba a realizar.
- Prueba de Carga: Validar el rendimiento bajo carga de trabajo normal y pico esperado.
- Prueba de Estrés: Identificar el punto de ruptura del sistema aumentando la carga más allá del máximo esperado.
- Prueba de Resistencia: Evaluar la estabilidad del sistema bajo una carga sostenida durante un período prolongado.
2. Preparación de Datos
¿Se necesitan datos específicos para ejecutar la prueba de manera realista?
- No, no se requieren datos específicos.
- Sí. Describe los requisitos a continuación:
(Ejemplo: Se necesitan 10,000 usuarios activos con reservas previas. Los datos se obtendrán anonimizando una muestra de producción y cargándola en el entorno de staging).
3. Autenticación y Autorización
¿Cómo se autenticará la herramienta de pruebas con los servicios?
- Los endpoints son públicos (sin autenticación).
- Token de Acceso (JWT, API Key): Se utilizará un token estático generado para la prueba.
- Credenciales de Usuario: Se utilizará un grupo de usuarios de prueba.
- Otro: (Especifica el método)
4. Herramientas
- Herramienta de Ejecución de Pruebas:
[por ejemplo, JMeter, Gatling, k6] - Herramienta de Monitoreo:
[por ejemplo, Grafana, Datadog, New Relic]
5. Monitoreo y Recopilación de Métricas
Describe cómo se monitorizarán y recopilarán los resultados de la prueba de rendimiento. Esto es crucial para entender el comportamiento del sistema bajo carga, especialmente cuando están involucrados procesos asíncronos, colas o trabajos en segundo plano.
CUÁNTO: Carga y Criterios de Aceptación
Esta sección define las métricas cuantitativas para el éxito de la prueba.
1. Perfil de Carga
Describe los escenarios de carga a simular.
[ ] Escenario 1: Carga Normal
- Descripción: Simula la actividad promedio de un día laboral.
- Usuarios Concurrentes:
[por ejemplo, 1,000] - Solicitudes por Segundo (TPS):
[por ejemplo, 500] - Duración:
[por ejemplo, 30 minutos]
[ ] Escenario 2: Carga Pico
- Descripción: Simula la actividad de un día de alta demanda (por ejemplo, inicio de un fin de semana festivo).
- Usuarios Concurrentes:
[por ejemplo, 5,000] - Solicitudes por Segundo (TPS):
[por ejemplo, 2,500] - Duración:
[por ejemplo, 1 hora]
2. Distribución de Tráfico por Endpoint
Define qué porcentaje del total de solicitudes irá a cada endpoint en cada escenario.
| Endpoint | Carga Normal (%) | Carga Pico (%) |
|---|---|---|
| (Ejemplo) /api/v2/properties/search | 80% | 90% |
3. Criterios de Aceptación (SLOs)
La prueba se considerará APROBADA si se cumplen las siguientes condiciones durante la ejecución del escenario de Carga Pico.
| Métrica | Umbral Aceptable |
|---|---|
| Tiempo de Respuesta (percentil 95) | Menos de [por ejemplo, 800] ms |
| Tasa de Error | Menos de [por ejemplo, 0.5] % |
| Uso de CPU (Servidores) | Menos de [por ejemplo, 80] % |
| Uso de Memoria (Servidores) | Menos de [por ejemplo, 85] % |
RESULTADOS: Documentación y Análisis Post-Prueba
Una vez completada la prueba, los resultados deben documentarse y compararse con los SLOs definidos. Cualquier desviación debe investigarse y abordarse, así como determinar si la prueba resultó satisfactoria, no satisfactoria o si se necesita una nueva prueba.
- Resultados de la Prueba: (Adjunta un informe detallado de los resultados, incluyendo gráficos y análisis).
- Cumplimiento de SLOs: (Indica si se cumplieron todos los SLOs definidos. Si no, proporciona detalles sobre las desviaciones y posibles causas).
- Acciones Recomendadas: (Lista cualquier acción correctiva o de seguimiento necesaria basada en los resultados de la prueba).
- Estado Final de la Prueba: (Selecciona una opción)
- Aprobada
- Aprobada con Observaciones
- No Aprobada - Requiere Acción Correctiva
- Requiere Nueva Prueba